A
- AGI
- Artificial General Intelligence
- Adaptable and Generalizable Intelligence
- ANE
- Apple Neural Engine
- ANE is a type of Neural Processing Unit (NPU). It’s like a GPU, but instead of accelerating graphics an NPU accelerates neural network operations such as convolutions and matrix multiplies.
- ANE is Apple’s marketing name for a cluster of highly specialized compute cores optimized for the energy-efficient execution of deep neural networks on Apple devices. It accelerates machine learning (ML) and artificial intelligence (AI) algorithms, offering tremendous speed, memory, and power advantages over the main CPU or GPU. The first ANE that debuted within Apple’s A11 chip in 2017’s iPhone X was powerful enough to support Face ID and Animoji. By comparison, the latest ANE in the A15 Bionic chip is 26 times faster than the first version. Nowadays, ANE enables features like offline Siri, and developers can use it to run previously trained ML models, freeing up the CPU and GPU to focus on tasks that are better suited to them.
- See: The Neural Engine: What do we know about it?
- See: What Is Apple’s Neural Engine and How Does It Work?
- See: Deploying Transformers on the Apple Neural Engine
- See the related term: Neural Processing Unit (NPU)
- ARC
- Abstraction and Reasoning Corpus
- ARC is a unique benchmark designed to measure AI skill acquisition and track progress towards achieving human-level AI introduced in 2019 by François Chollet, a software engineer and AI researcher at Google. Chollet’s influential paper, On the Measure of Intelligence, defines intelligence as an agent’s ability to adapt to a constantly changing environment and respond appropriately in novel situations.
- See: ARC
- ASR
- Automatic Speech Recognition
B
- BERT
- Bidirectional Encoder Representations from Transformers (from Google)
- BERT is the first deeply bidirectional, unsupervised language representation, pre-trained using only a plain text corpus (in this case, Wikipedia)
- See: Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing
- See: Getting started with the built-in BERT algorithm
- BERT Score
- One main disadvantage of using metrics such as BLEU or ROUGE is the fact that the performance of text generation models are dependent on exact matches. Exact matches might be important for use-cases like machine translation, however for generative AI models that try to create meaningful and similar texts to corpus data, exact matches might not be very accurate.
- Hence, instead of exact matches, BERTScore is focused on the similarity between reference and generated text by using contextual embeddings. The main idea behind contextual embeddings is to understand the meaning behind the reference and candidate text respectively and then compare those meanings.
- See: Monitoring Text-Based Generative AI Models Using Metrics Like Bleu Score
- See the related term: BLEU, ROUGE, METEOR
- BLEU Score
- Bilingual Evaluation Understudy
- BLEU is a precision-focused metric that measures the n-gram overlap between the generated text and the reference text. The score also considers a brevity penalty where a penalty is applied when the machine-generated text is too short compared to reference text. It is a metric that is generally used for machine translation performance. The score ranges from 0 to 1, with higher scores indicating greater similarity between the generated text and the reference text.
- See: Monitoring Text-Based Generative AI Models Using Metrics Like Bleu Score
- See the related term: BERT, ROUGE, METEOR
- BM25
- Best Match 25 (or Okapi BM25)
- A ranking function used by search engines to estimate the relevance of documents to a given search query. It is based on the probabilistic retrieval framework developed in the 1970s and 1980s by Stephen E. Robertson, Karen Spärck Jones, and others.
- The fuller name, Okapi BM25, includes the name of the first system to use it, which was the Okapi information retrieval system, implemented at London’s City University in the 1980s and 1990s.
- See: Okapi BM25
- See: Rank-BM25: A two line search engine
C
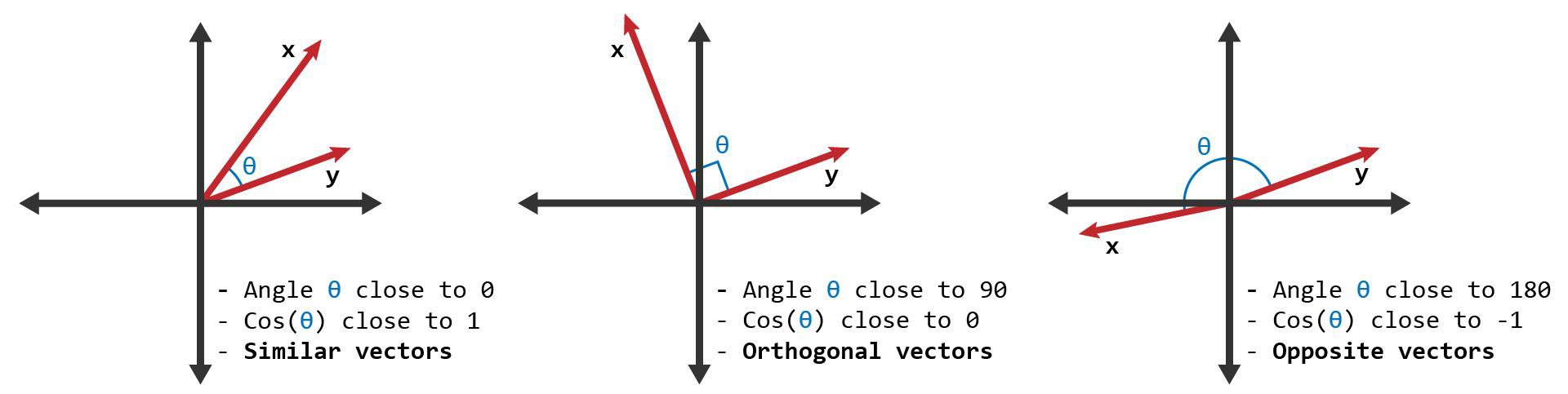
- Cosine Similarity
- Cosine similarity measures the similarity between two vectors of an inner product space. It is measured by the cosine of the angle between two vectors and determines whether two vectors are pointing in roughly the same direction, ignoring differences in their magnitude or scale. It is often used to measure document similarity in text analysis.
- See: What is Cosine Similarity?
- CoT Prompting
- Chain-of-thought (CoT) Prompting
- A technique for improving the reasoning ability of large language models by prompting them to generate a series of intermediate steps that lead to the final answer of a multi-step problem. It was first proposed by Google researchers in 2022. CoT prompting has been shown to improve the performance of LLMs on average on both arithmetic and commonsense tasks compared to standard prompting methods. CoT prompting is an emergent property of model scale, meaning it works better with larger and more powerful language models.
- See: Language Models Perform Reasoning via Chain of Thought
- Codex
- A fine-tuned GPT-3 model developed by OpenAI that parses natural language and generates programming code in response and has been used to power GitHub Copilot
- ControlNet
- A neural network structure to control diffusion models by adding extra conditions
- See: Adding Conditional Control to Text-to-Image Diffusion Models
- See: lllyasviel/ControlNet
D
- DAN
- Do Anything Now (a form of LLM-chatbot jailbreak)
- See: DAN 5.0
- DoRA
- Weight-Decomposed Low-Rank Adaptation
- Among the widely used parameter-efficient finetuning (PEFT) methods, LoRA and its variants have gained considerable popularity because of avoiding additional inference costs. However, there still often exists an accuracy gap between these methods and full fine-tuning (FT). In this work, we first introduce a novel weight decomposition analysis to investigate the inherent differences between FT and LoRA. Aiming to resemble the learning capacity of FT from the findings, we propose Weight-Decomposed LowRank Adaptation (DoRA).
- DoRA decomposes the pre-trained weight into two components, magnitude and direction, for fine-tuning, specifically employing LoRA for directional updates to efficiently minimize the number of trainable parameters. By employing DoRA, we enhance both the learning capacity and training stability of LoRA while avoiding any additional inference overhead. DoRA consistently outperforms LoRA on fine-tuning LLaMA, LLaVA, and VL-BART on various downstream tasks, such as commonsense reasoning, visual instruction tuning, and image/video-text understanding.
- See: https://arxiv.org/abs/2402.09353
- See: https://magazine.sebastianraschka.com/p/lora-and-dora-from-scratch
- See the related term: LoRA
- DP
- Differential Privacy
- DP is a mathematical definition of what it means to have privacy. It is not a specific process like de-identification, but a property that a process can have. For example, it is possible to prove that a specific algorithm “satisfies” differential privacy.
- DP is a system for publicly sharing information about a dataset by describing the patterns of groups within the dataset while withholding information about individuals in the dataset. An algorithm is differentially private if an observer seeing its output cannot tell if a particular individual’s information was used in the computation. Differentially private algorithms are used by some government agencies to publish demographic information or other statistical aggregates while ensuring confidentiality of survey responses, and by companies to collect information about user behavior while controlling what is visible even to internal analysts.
- See: Differential Privacy
- See: DP for privacy-preserving data analysis
- See the related term: Secure Multi-Party Computation (SMPC) and Secure Aggregation
- DPR
- Dense Passage Retrieval (sometimes shortened as Dense Retrieval)
- A technique for open-domain question answering that aims to retrieve relevant passages from a large corpus of unstructured text. Unlike traditional information retrieval (IR) techniques that rely on sparse representations, DPR uses dense representations adapted from deep neural networks, which are then used to encode text passages and questions. The basic idea of DPR is to precompute dense vector representations of text and store them in a search index. DPR uses dense representations comprehended from deep neural networks to encode text passages and questions. Given a user’s query, DPR retrieves the most relevant passages from the index based on the similarity between their representations and the representation of the query. Once the relevant passages are retrieved, a downstream model can extract the answers to the question asked. This is done because dense representations have a great ability to capture the semantic similarity between text passages, which leads to precise retrieval. Also, by precomputing the representations and storing them in an index, DPR can achieve faster retrieval times than traditional techniques that compute similarity on the fly.
- See: Dense Passage Retrieval for Open-Domain Question Answering
- See: Build a DPR model for open-domain QA
E
- Embeddings
- See the related term: Vector Embedding
- ERNIE
- Enhanced Representation through kNowledge IntEgration with 260B parameters (from Baidu)
- See: Introducing PCL-BAIDU Wenxin (ERNIE 3.0 Titan), the World’s First Knowledge Enhanced Multi-Hundred-Billion Model
F
- Federated Learning
- Enables machine learning on distributed data by moving the training to the data, instead of moving the data to the training.
- Here’s how it works: (0) Initialize the global model parameters on the server; (1) Send the model parameters to a number of organizations or devices (client nodes); (2) Train model locally on the data of each organization or device (client node); (3) Return the updated model parameters back to the server; (4) On the server, aggregate the model updates (for example, by averaging them) into a new global model; (5) Repeat steps 1 to 4 until the model converges.
- See: What is Federated Learning?
- FNN
- Feedforward Neural Networks
- A feedforward neural network (FNN) is the simpler of the two broad types of artificial neural network, characterized by direction of the flow of information between its layers. In contrast to bi-directional recurrent neural networks, it is uni-directional, meaning that the information in the model flows in only one direction—forward—from the input nodes, through the hidden nodes (if any) and to the output nodes, without any cycles or loops.
- See the related term: Recurrent Neural Networks (RNN)
- See: Feedforward neural network
- Fine Tuning
- Re-training a pre-trained language model with custom data to update the model weights to account for the characteristics of the domain data resulting in predictions that are more adapted to the dataset
- See: Fine-Tuning for Domain Adaptation in NLP
- Foundation Models
- Foundation models are large-scale machine learning models pre-trained on extensive datasets. These models are trained to learn general-purpose representations across various data modalities, including text, images, audio, and video. Their key strengths lie in their size, pre-training, self-supervised learning, generalization, and adaptability.
- See: Foundation Models: The Building Blocks of Next-Gen AI
- Foundation Model Transparency Index
- A comprehensive assessment of the transparency of foundation model developers from Stanford’s Center for Research on Foundation Models
- Context. Foundation models like GPT-4 and Llama 2 are used by millions of people. While the societal impact of these models is rising, transparency is on the decline. If this trend continues, foundation models could become just as opaque as social media platforms and other previous technologies, replicating their failure modes. Design. We introduce the Foundation Model Transparency Index to assess the transparency of foundation model developers. We design the Index around 100 transparency indicators, which codify transparency for foundation models, the resources required to build them, and their use in the AI supply chain. Execution. For the 2023 Index, we score 10 leading developers against our 100 indicators. This provides a snapshot of transparency across the AI ecosystem. All developers have significant room for improvement that we will aim to track in the future versions of the Index.
- See: The Foundation Model Transparency Index
G
- GPT
- Generative Pre-trained Transformer
- GPT-1 (117M), GPT-2 (1.5B), GPT-3 (175B), GPT-3.5 (175B), GPT-4 (undisclosed)
- Generations of GPTs (from OpenAI), with GPT-4 being made publicly available on March 14, 2023
- See: The Journey of Open AI GPT models
- See: How GPT-3 Works
- See: GPT-4 System Card
PDF
H
- Hyperparameters
- Parameters whose values control the learning process and affect how well a model trains but are not part of the resulting model
- Examples include: the number of training iterations (epochs), number of neural networks hidden layers, or train-test split ratio
- See: Parameters and Hyperparameters in Machine Learning and Deep Learning
I
- ICL
- In-Context Learning
- A phenomenon in which a large language model learns to accomplish a task after seeing only a few examples despite the fact that it wasn’t trained for that task. In-context learning allows users to quickly build models for a new use case without worrying about fine-tuning and storing new parameters for each task.
- See: Solving a machine-learning mystery
- See: How does in-context learning work?
K
- Knowledge Distillation
- The process of transferring the knowledge from a large unwieldy machine learning or deep learning model or set of models to a single smaller model that can be practically deployed under real-world constraints without loss of validity
- See: Knowledge Distillation: Principles, Algorithms, Applications
- It is a model compression method in which a small model is trained to mimic a pre-trained, larger model (or ensemble of models), sometimes referred to as “teacher-student” setting, where the large model is the teacher and the small model is the student
- See: Compressing Models » Knowledge Distillation
L
- LAION
- Large-scale Artificial Intelligence Open Network
- See: https://laion.ai/
- LaMDA
- Language Model for Dialogue Applications with 137B parameters (from Google)
- See: LaMDA: Towards Safe, Grounded, and High-Quality Dialog Models for Everything
- LLaMA
- Large Language Model Meta AI with 7B, 13B, 33B, and 65B parameters (from Meta)
- See: Introducing LLaMA: A foundational, 65-billion-parameter large language model
- See: LLaMA: Open and Efficient Foundation Language Models
- See: Reference code in Python
- LLM
- Large Language Model
- Logit Layer
- The last layer of a neural network that transforms classification probabilities into real numbers as inputs for the following softmax function
- A logit function maps probabilities [0, 1] to [-∞, +∞] and is an inverse to the sigmoid or activation function
- See: Historical perspective of logits
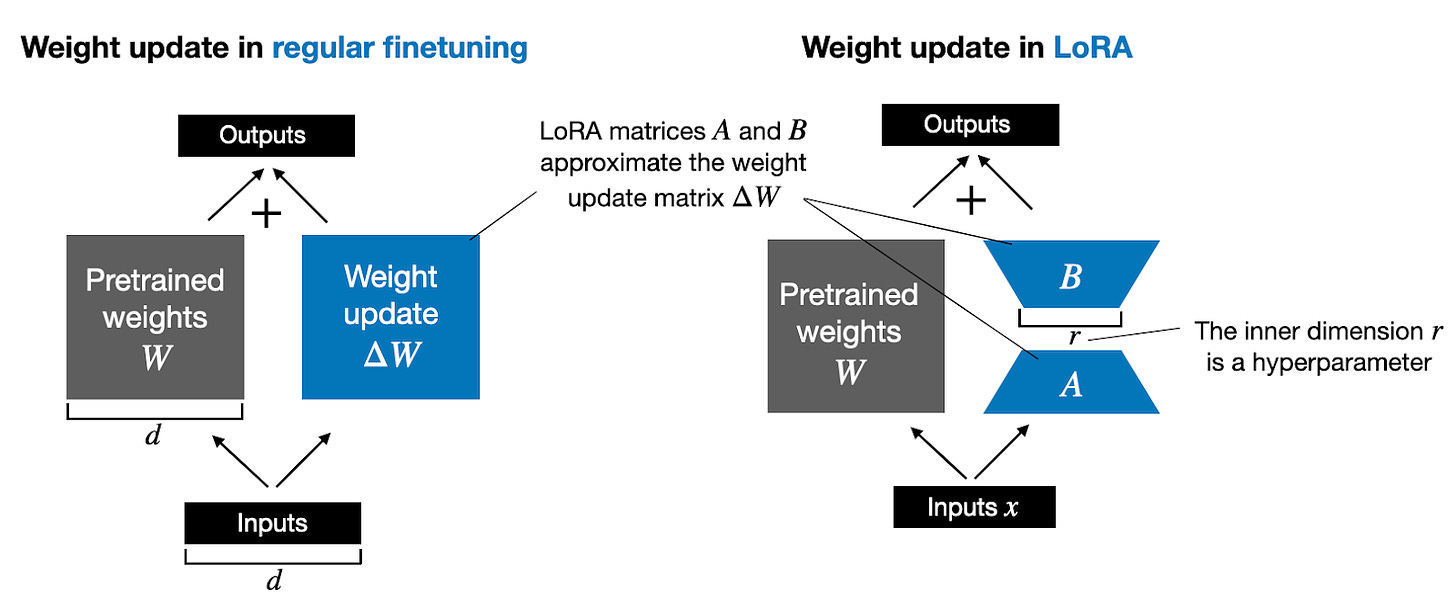
- LoRA
- Low-Rank Adaptation of Large Language Models
- LoRA freezes the pre-trained LLM weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks to make fine-tuning a large model more feasible
- See: LoRA: Low-Rank Adaptation of Large Language Models
- See the related term: DoRA
- LSTM
- Long Short Term Memory (a special kind of RNN)
- See: Understanding LSTM Networks
M
- METEOR Score
- Metric for Evaluation of Translation with Explicit Ordering
- METEOR is a metric that measures the quality of generated text based on the alignment between the generated text and the reference text. The metric is based on the harmonic mean of unigram precision and recall, with recall weighted higher than precision.
- While the main difference between rouge and bleu is that bleu score is precision-focused and ROUGE score focuses on recall, the METEOR metric on the other hand was designed to fix some of the problems found in the more popular BLEU and ROUGE metrics and also produce good correlation with human judgment at the sentence or segment level.
- See: Monitoring Text-Based Generative AI Models Using Metrics Like Bleu Score
- See: METEOR
- See the related terms: BERT, BLEU, ROUGE
- MMR
- Maximal Marginal Relevance
- In document retrieval and text summarization, MMR is a criteria used to reduce redundancy while maintaining query relevance in reranking retrieved documents and in selecting appropriate passages for text summarization. MMR maximizes the margin relevance of the documents and iteratively select the document that is not only relevant to the query but also dissimilar to the previously selected documents.
- See: The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries
- Model Cards
- Short documents accompanying trained machine learning models that provide benchmarked evaluation in a variety of conditions, such as across different cultural, demographic, or phenotypic groups (e.g., race, geographic location, sex, Fitzpatrick skin type) and intersectional groups (e.g., age and race, or sex and Fitzpatrick skin type) that are relevant to the intended application domains. Model cards also disclose the context in which models are intended to be used, details of the performance evaluation procedures, and other relevant information.
- See the related term: System Cards
- See: Model Cards for Model Reporting
- See: The value of a shared understanding of AI models
- MoE
- Mixture of Experts
- MoE is a machine learning technique where multiple expert networks (learners) are used to divide a problem space into homogeneous regions. It differs from ensemble techniques in that typically only one or a few expert models will be run, rather than combining results from all models.
- See: A Gentle Introduction to Mixture of Experts Ensembles
N
- NeRF
- Neural Radiance Field
- A fully-connected neural network that can generate novel views of complex 3D scenes, based on a partial set of 2D images. It is trained to use a rendering loss to reproduce input views of a scene. It works by taking input images representing a scene and interpolating between them to render one complete scene. NeRF is a highly effective way to generate images for synthetic data.
- See: Representing Scenes as Neural Radiance Fields for View Synthesis
- NPU
- Neural Processing Unit
- NPU is a specialized processor designed to accelerate the performance of common machine learning tasks and typically of neural networks applications.
- See: Working with Neural Processing Units (NPUs) using OpenCV
- See: Deep learning processor
- NTTS
- Neural Text-to-Speech
O
- OK-VQA
- Outside Knowledge Visual Question Answering
- See: https://okvqa.allenai.org/
P
- PaLM
- Pathways Language Model (from Google)
- A 540B parameter, dense decoder-only Transformer model trained with Google’s Pathways system
- Pathways is a single model that could generalize across domains and tasks (in contrast to being overspecialized) while being highly efficient
- See: Scaling to 540 Billion Parameters for Breakthrough Performance
- See: Introducing Pathways: A next-generation AI architecture
- Prompt Injection
- A family of related computer security exploits carried out by getting a machine learning model (such as an LLM) which was trained to follow human-given instructions to follow instructions provided by a malicious user. This stands in contrast to the intended operation of instruction-following systems, wherein the ML model is intended only to follow trusted instructions (prompts) provided by the ML model’s operator. Common types of prompt injection attacks are: jailbreaking, which may include asking the model to roleplay a character, to answer with arguments, or to pretend to be superior to moderation instructions; prompt leaking, in which users persuade the model to divulge the prompt normally hidden from the users; and token smuggling, a type of a jailbreaking attack in which the nefarious prompt is wrapped in a code writing task.
- See: Prompt engineering
Q
- Quantization
- The process of reducing the precision of a neural networks weights, biases, and activations such that they consume less memory
- See: Neural Network Quantization: What Is It and How Does It Relate to TinyML?
R
- RAG
- Retrieval Augmented Generation
- An architecture that combines an information retrieval component with generative AI to implement open domain question-answering tasks. Given the prompt “When did the first mammal appear on Earth?” for instance, RAG might surface documents for “Mammal,” “History of Earth,” and “Evolution of Mammals.” These supporting documents are then concatenated as context with the original input and fed to the generative model that produces the actual output. RAG thus has two sources of knowledge: the knowledge that the generative models store in their parameters (parametric, “closed-book” memory) and the knowledge stored in the corpus from which RAG retrieves passages (nonparametric, “open-book” memory).
- See: Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models
- See: Retrieval Augmented Generation with Huggingface Transformers and Ray
- See: etrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- RL
- Reinforcement Learning (in contrast to supervised learning and unsupervised learning)
- RLHF
- Reinforcement Learning from Human Feedback
- Use human feedback for a language model’s generated text as a measure of its performance and as a loss function to optimize the model
- See: Illustrating Reinforcement Learning from Human Feedback
- RNN
- Recurrent Neural Networks
- A class of neural networks that allow previous outputs to be used as inputs while having hidden states
- See: Recurrent Neural Networks cheatsheet
- ROUGE Score
- Recall Oriented Understudy for Gisting Evaluation
- ROUGE is a metric that measures the overlap between the generated text and the reference text in terms of recall. Rouge comes in three types: rouge-n, the most prevalent form that detects n-gram overlap; rouge-l, which identifies the Longest Common Subsequence and rouge-s, which concentrates on skip grams. n-rouge is the most frequently used type with the following formula:

- The main difference between ROUGE and BLEU is that BLEU score is precision-focused whereas ROUGE score focuses on recall.
- See: Monitoring Text-Based Generative AI Models Using Metrics Like Bleu Score
- See the related terms: BERT, BLEU, METEOR
S
- Secure Aggregation
- A class of Secure Multi-Party Computation (SMPC) algorithms wherein a group of mutually distrustful parties u ∈ U each hold a private value x_u and collaborate to compute an aggregate value, such as the sum_{u∈U} x_u, without revealing to one another any information about their private value except what is learnable from the aggregate value itself.
- See: Practical Secure Aggregation for Federated Learning on User-Held Data
- See the related terms: Secure Multi-Party Computation (SMPC) and Differential Privacy (DP)
- SMPC
- Secure Multi-Party Computation
- SMPC is a subfield of cryptography with the goal of creating methods for parties to jointly compute a function over their inputs while keeping those inputs private.
- SMPC is a cryptographic protocol that distributes a computation across multiple parties where no individual party can see the other parties’ data.
- See the related terms: Secure Aggregation and Differential Privacy (DP)
- Softmax Function
- A function that maps the values in [-∞, +∞] to [0, 1] and normalizes the total sum of the output vector to 1
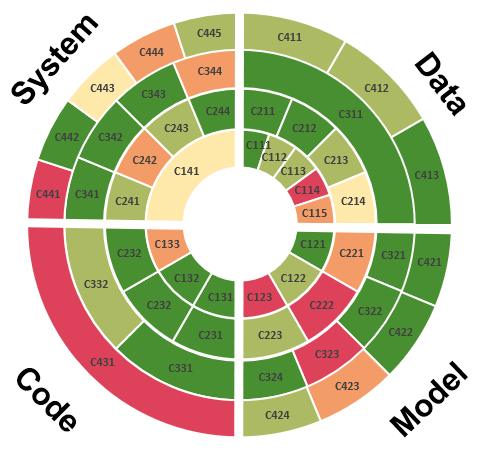
- System Cards
- A visual representation of the results of formal audits of artificial intelligence-based decision-aiding systems based on a system accountability benchmark. A System Card is the overall outcome of the evaluation for a specific machine learning-based automated decision system visualized as four concentric circles where each circle corresponds to a column in the framework for System Accountability Benchmark.
- See the related term: Model Cards
- See: System Cards for AI-Based Decision-Making for Public Policy
- See: System Cards, a new resource for understanding how AI systems work
- See: System Cards for AI-Based Decision-Making for Public Policy
- SSL
- Self-Supervised Learning (in contrast to supervised learning)
- SSL is an unsupervised Machine Learning method where a model, when fed with unstructured data as input, generates data labels automatically, which are further used in subsequent iterations as ground truths. This allows the model to learn complex patterns automatically from unlabeled data.
- See: The Beginner’s Guide to Self-Supervised Learning
T
- Temperature
- A parameter used in natural language processing models to increase or decrease the “confidence” a model has in its most likely response
- See: What is Temperature in NLP?
- A hyperparameter of LSTMs and generally, neural networks used to control the randomness of predictions by scaling the logits before applying softmax
- See: Softmax Temperature
- Transformer
- A deep learning model that adopts the mechanism of self-attention, differentially weighting the significance of each part of the input data. It is used primarily in the fields of natural language processing and computer vision. Like recurrent neural networks (RNNs), transformers are designed to process sequential input data, such as natural language, to perform translation and text summarization, as examples. However, unlike RNNs, transformers process the entire input all at once.
- See the related terms: RNN, LSTM, ViT
- See: Attention Is All You Need
- See: How Transformers Work
- See: Transformers Explained Visually
- See: The Illustrated Transformer
V
- Vector Database
- A vector database indexes and stores vector embeddings for fast retrieval and similarity search, with capabilities like CRUD operations, metadata filtering, and horizontal scaling. Vector databases are purpose-built to handle the unique structure of vector embeddings. They index vectors for easy search and retrieval by comparing values and finding those that are most similar to one another. Vector databases excel at similarity search, or “vector search.” Vector search enables users to describe what they want to find without having to know which keywords or metadata classifications are ascribed to the stored objects. Vector search can also return results that are similar or near-neighbor matches, providing a more comprehensive list of results that otherwise may have remained hidden.
- See: What is a Vector Database?
- Vector Embedding
- In NLP, an embedding is a vector of real numbers corresponding to words or phrases in a vocabulary. Vectorization is the process of converting words into the corresponding vectors in the trained models. Word embeddings help in computing similar words, classifying text passages, grouping or clustering documents or document chunks, and extracting features from text passages. To identify similar words using vectors, we use techniques that calculates Euclidean Distance or Cosine Distance of text passages in the vector space.
- Examples of embedding architectures include: Word2Vec (Google), Fasttext (Meta), and Glove (Stanford)
- See the related term: Cosine Similarity
- See: Understanding NLP Word Embeddings — Text Vectorization
- See: What are Vector Embeddings?
- See: Gensim, a Python library implementing Word2Vec for topic modelling, document indexing and similarity retrieval with large corpora
- ViT
- Vision Transformer
- A transformer that is targeted at vision processing tasks such as image recognition. A pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
- See the related term: Transformer
- See: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- See: Vision Transformer (ViT)
- VLM
- Vision-Language Models
- A vision-language model is a fusion of vision and natural language models. It ingests images and their respective textual descriptions as inputs and learns to associate the knowledge from the two modalities. The vision part of the model captures spatial features from the images, while the language model encodes information from the text.
- The data from both modalities, including detected objects, spatial layout of the image, and text embeddings, are mapped to each other. For example, if the image contains a bird, the model will learn to associate it with a similar keyword in the text descriptions. This way, the model learns to understand images and transforms the knowledge into natural language (text) and vice-versa.
- See: Guide to Vision-Language Models (VLMs)
Z
- Zero-shot, one-shot, and few-shot learning
- These are all techniques that allow a machine learning model to make predictions for new classes with limited labeled data. The choice of technique depends on the specific problem and the amount of labeled data available for new categories or labels (classes).
- In one-shot learning each new class has one labeled example. The goal is to make predictions for the new classes based on this single example.
- In few-shot learning there is a limited number of labeled examples for each new class. The goal is to make predictions for new classes based on just a few examples of labeled data.
- In zero-shot learning there is absolutely no labeled data available for new classes. The goal is for the algorithm to make predictions about new classes by using prior knowledge about the relationships that exist between classes it already knows. In the case of large language models (LLMs) like ChatGPT, for example, prior knowledge is likely include semantic similarities.
- In many real-world scenarios, it is not feasible to collect and label large amounts of data for every possible class or concept that a model may encounter. Allowing models to handle new and unseen classes with limited or no additional labeled data can improve scalability and help reduce the costs associated with labeling and annotating data.
- See: What Does Zero-Shot, One-Shot, Few-Shot Learning Mean?